在作物育种中,植物表型是对植物特有的“可见”或表型特征的详细研究。它包括计算杂交实验产生的植物数量并对后代或后代显示的特征进行分级。然后将具有理想性状的后代杂交以产生下一代作物,并重复该过程以增强作物品种。传统的植物表型分析方法通常缺乏可扩展性、准确性,并且非常耗费人力。这给作物育种计划带来了一定的瓶颈。
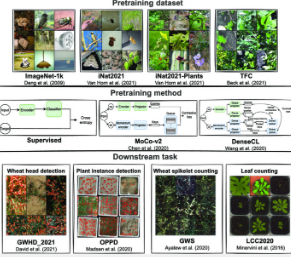
然而,随着技术进步和全球粮食安全维持人口增长的相关需求,新方法正在慢慢占据中心舞台。其中包括基于成像的技术,这些技术可以捕捉照片、使用机器学习工具提取特征并将结果与可用数据库进行比较,从而在更短的时间内以更高的准确性执行表型分析任务。目前,大多数机器学习方法都遵循带有标记数据集的监督学习框架,这可能既昂贵又耗时。自监督学习 (SSL) 是一种机器学习方法,可减少对标记数据的需求。尽管 SSL 研究激增,但在基于图像的植物表型任务中仍然缺乏 SSL 应用。
在一项新研究中,由加拿大萨斯喀彻温大学 Ian Stavness 副教授领导的研究小组对 2 种 SSL 方法的性能进行了基准测试,以改进植物表型分析。该研究声称自监督方法可能比监督方法对预训练数据集冗余更敏感,该研究发表于2023年 4 月 3 日的植物现象学第 5 卷。Stavness 副教授解释说:“这些结果强调了在为植物表型任务训练模型时注意数据集冗余的重要性,尤其是在使用 SSL 方法时。”
本研究使用小麦作为模型作物,将传统的监督(预训练)方法与两种 SSL 方法——动量对比 (MoCo) v2 和密集对比学习 (DenseCL) 进行比较。所有学习方法都受制于 4 个表型任务:小麦头部检测、植物实例检测、小麦小穗计数和叶计数。该团队发现,有监督的预训练为除叶子计数之外的所有任务生成了性能最佳的模型。
与监督方法不同,对比 SSL 方法严重依赖于大型标记和注释数据库来执行表型任务。该算法经过训练,可以将正样本拉近,将负样本推开,从而增加正样本的强度,并训练算法识别更多这些样本。MoCo v2 的功能是优化样本的全局图像级特征,而 DenseCL 则专注于局部像素级特征。这两种方法在为所需任务训练模型的内部表示的上下文中显示出可比的性能。
为了使预训练算法表现良好,本质上需要一个专门但多样化的数据集。然而,当面对大型数据集的冗余时,自监督方法在准确性和灵敏度方面表现更好。鉴于该研究的结论主要是根据经验观察得出的,几乎没有理论依据,作者希望将他们的工作扩展到作物育种试验中,这将涉及更多细粒度的信息,并帮助他们训练算法以用于实际应用和大规模商业化。
Stavness 副教授总结说:“通过将SSL 与联合嵌入空间中的基因型和环境数据对齐,SSL 可以潜在地用于学习更丰富的植物表型表示。我们希望这项基准或评估研究能够指导从业者开发更好的基于图像的植物表型 SSL 方法”。
标签:
免责声明:本文由用户上传,如有侵权请联系删除!