在史前社会中,人类倾向于向我们内部群体的成员或更有声望的个人学习,因为这些信息更有可能可靠并导致群体成功。然而,随着多样化和复杂的现代社区的出现,尤其是在社交媒体中,这些偏见变得不那么有效。例如,我们在网上联系的人可能不一定值得信任,而且人们很容易在社交媒体上假装威望。在8 月 3日《认知科学趋势》杂志上发表的一篇评论中,一群社会科学家描述了社交媒体算法的功能如何与旨在促进合作的人类社会本能不一致,这可能导致大规模的两极分化和错误信息。
“现在 Twitter 和 Facebook 上的几项用户调查表明,大多数用户对他们看到的政治内容感到疲惫不堪。很多用户都不满意,而且在涉及选举和错误信息传播时,Twitter 和 Facebook 必须面对很多声誉问题。”凯洛格学院社会心理学家、第一作者 William Brady (@william__brady) 说道。管理在西北。
“我们想要进行一项系统回顾,试图帮助理解人类心理和算法如何相互作用,从而产生这些后果,”布雷迪说。“这次审查带来的问题之一是社会学习视角。作为社会心理学家,我们不断研究如何向他人学习。如果我们想了解算法如何影响我们的社交互动,这个框架至关重要。”
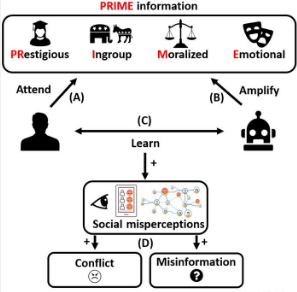
人类倾向于以一种通常促进合作和集体解决问题的方式向他人学习,这就是为什么他们倾向于从他们认为是内部群体一部分的人和他们认为有声望的人那里学习更多。此外,当学习偏见首次出现时,优先考虑道德和情感信息非常重要,因为这些信息更有可能与执行群体规范和确保集体生存相关。
相比之下,算法通常会选择能够提高用户参与度的信息,以增加广告收入。这意味着算法放大了人类偏向学习的信息,并且它们可以用研究人员所说的著名、内部群体、道德和情感(PRIME)信息使社交媒体信息过度饱和,无论内容的准确性或群体观点的代表性如何。因此,极端的政治内容或有争议的话题更有可能被放大,如果用户不接触外界意见,他们可能会发现自己对不同群体的大多数意见有错误的理解。
“该算法并不是为了破坏合作而设计的,”布雷迪说。“只是目标不同而已。在实践中,当你将这些功能放在一起时,最终会产生一些潜在的负面影响。”
为了解决这个问题,研究小组首先提出社交媒体用户需要更多地了解算法的工作原理以及为什么某些内容会出现在他们的提要上。社交媒体公司通常不会披露其算法如何选择内容的完整细节,但一开始可能会提供解释,解释为什么向用户显示特定的帖子。例如,是因为用户的朋友正在关注该内容还是因为该内容普遍受欢迎?在社交媒体公司之外,研究团队正在开发自己的干预措施,以教导人们如何成为更有意识的社交媒体消费者。
此外,研究人员建议社交媒体公司可以采取措施改变其算法,以便更有效地培育社区。算法不是仅仅偏爱 PRIME 信息,而是可以对放大 PRIME 信息的数量设置限制,并优先向用户呈现不同的内容。这些变化可以继续放大吸引人的信息,同时防止更多两极分化或政治极端的内容在提要中出现过多的情况。
“作为研究人员,我们了解公司在进行这些变革及其盈利时所面临的压力。这就是为什么我们实际上认为这些变化理论上仍然可以保持参与度,同时也不允许这种 PRIME 信息的过度呈现,”Brady 说。“通过这样做实际上可能会改善用户体验。”
标签:
免责声明:本文由用户上传,如有侵权请联系删除!